20 Enrichment score heatmaps
A very common approach to make sense of your cells is to query several list of marker genes, retrieved from literature, and compute how enriched each cell is in each given list of genes. This is achieved by using Seurat::AddModuleScore. The scores can be then visualized as a Feature plot, but one can also aggregate the enrichment scores by any variable of interest, for instance the different clusters in the sample.
This kind of heatmaps can be easily computed using SCpubr::do_EnrichmentHeatmap():
20.1 Single grouping variable
# Define list of genes.
genes <- list("Naive CD4+ T" = c("IL7R", "CCR7"),
"CD14+ Mono" = c("CD14", "LYZ"),
"Memory CD4+" = c("S100A4"),
"B" = c("MS4A1"),
"CD8+ T" = c("CD8A"),
"FCGR3A+ Mono" = c("FCGR3A", "MS4A7"),
"NK" = c("GNLY", "NKG7"),
"DC" = c("FCER1A", "CST3"),
"Platelet" = c("PPBP"))
# Default parameters.
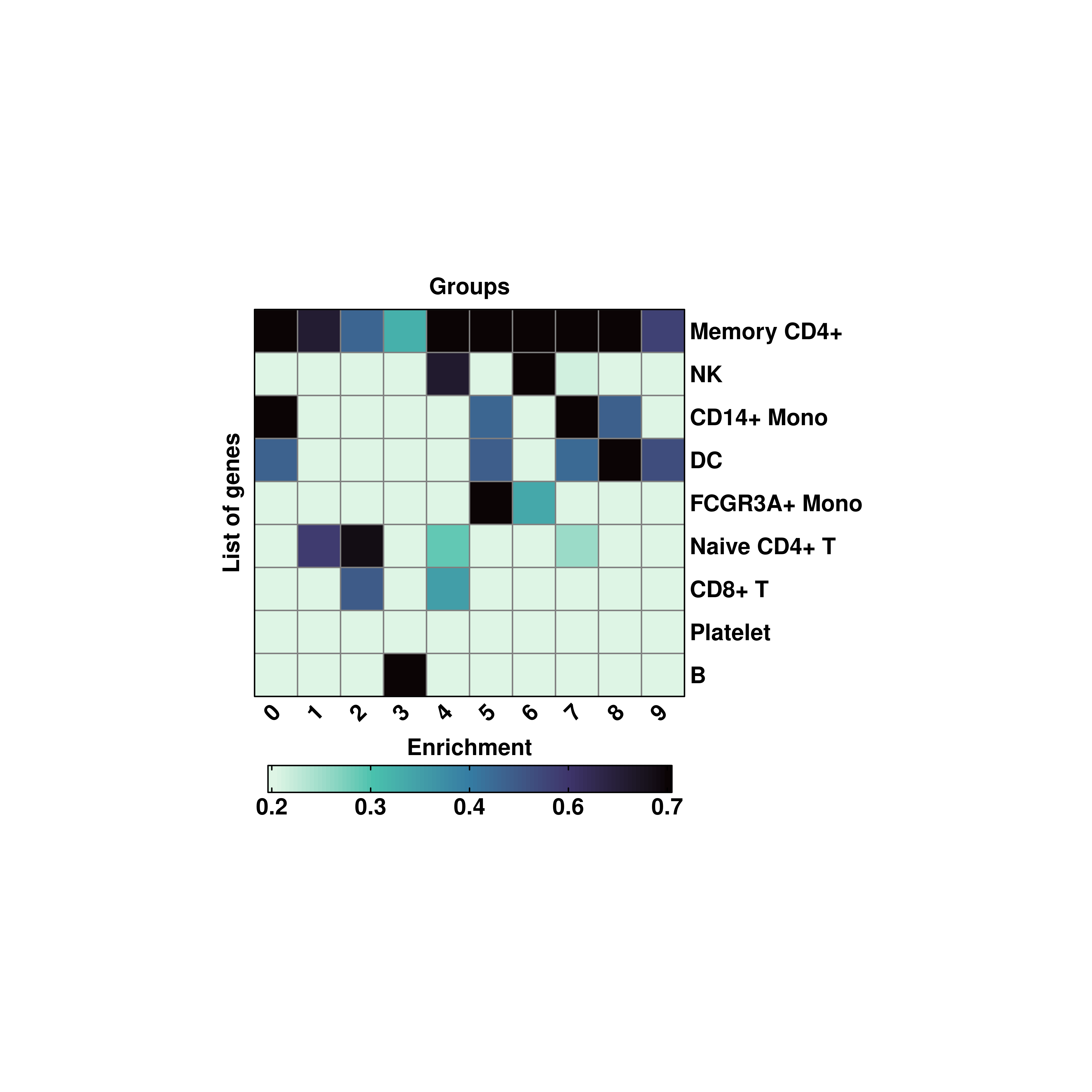
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
viridis_direction = -1)
p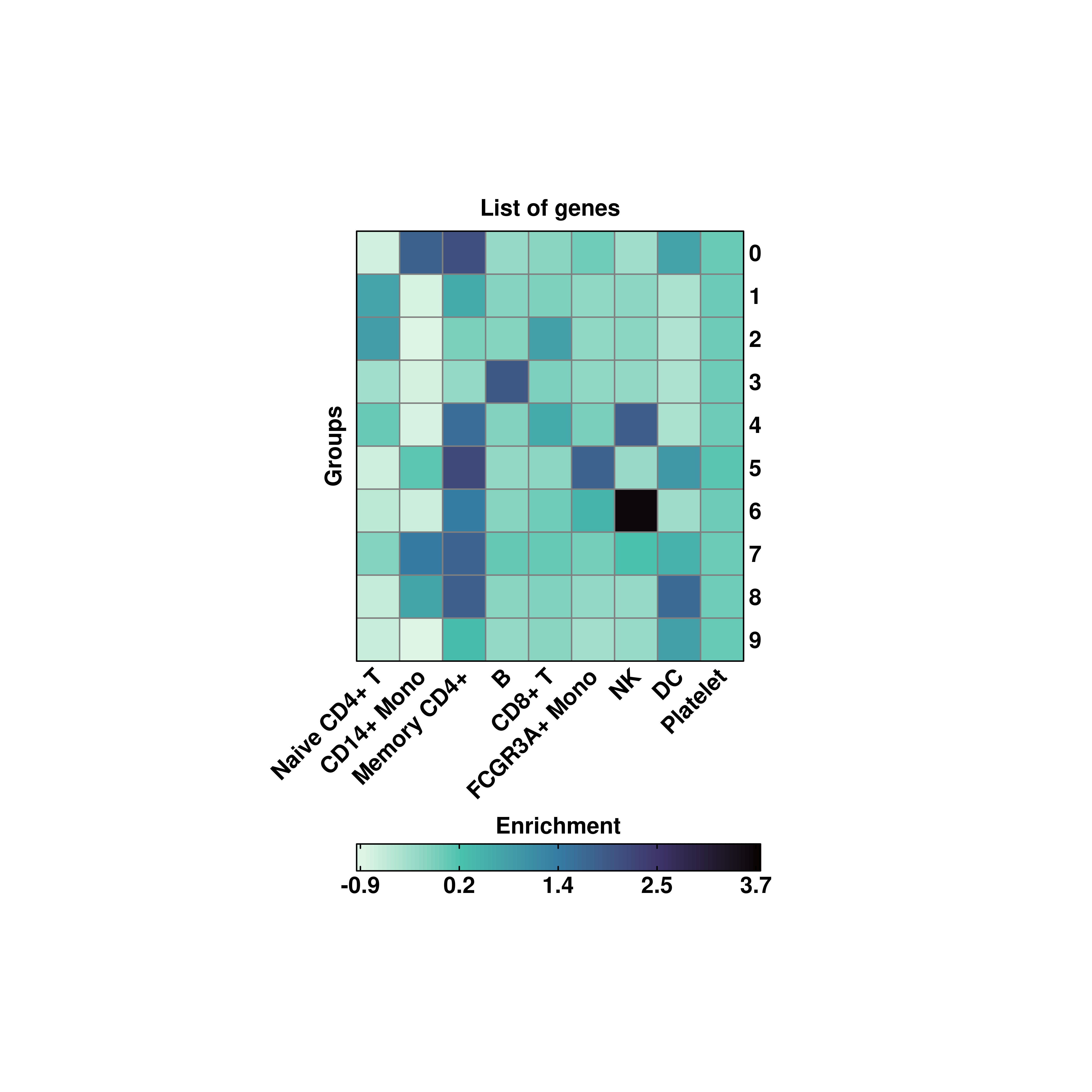
In these cases, inverting the color scale with viridis_direction = -1 is the best choice as makes it easir to identify dark colors in the heatmap and they stand out more than it would do when it comes to using light colors on dark background.
By default, SCpubr::do_EnrichmentHeatmap aggregates the values by the current identity. However, other metadata variables can be used to aggregate for. For this, provide the name to group.by parameter.
# Custom aggregated values.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
group.by = "orig.ident",
viridis_direction = -1)
p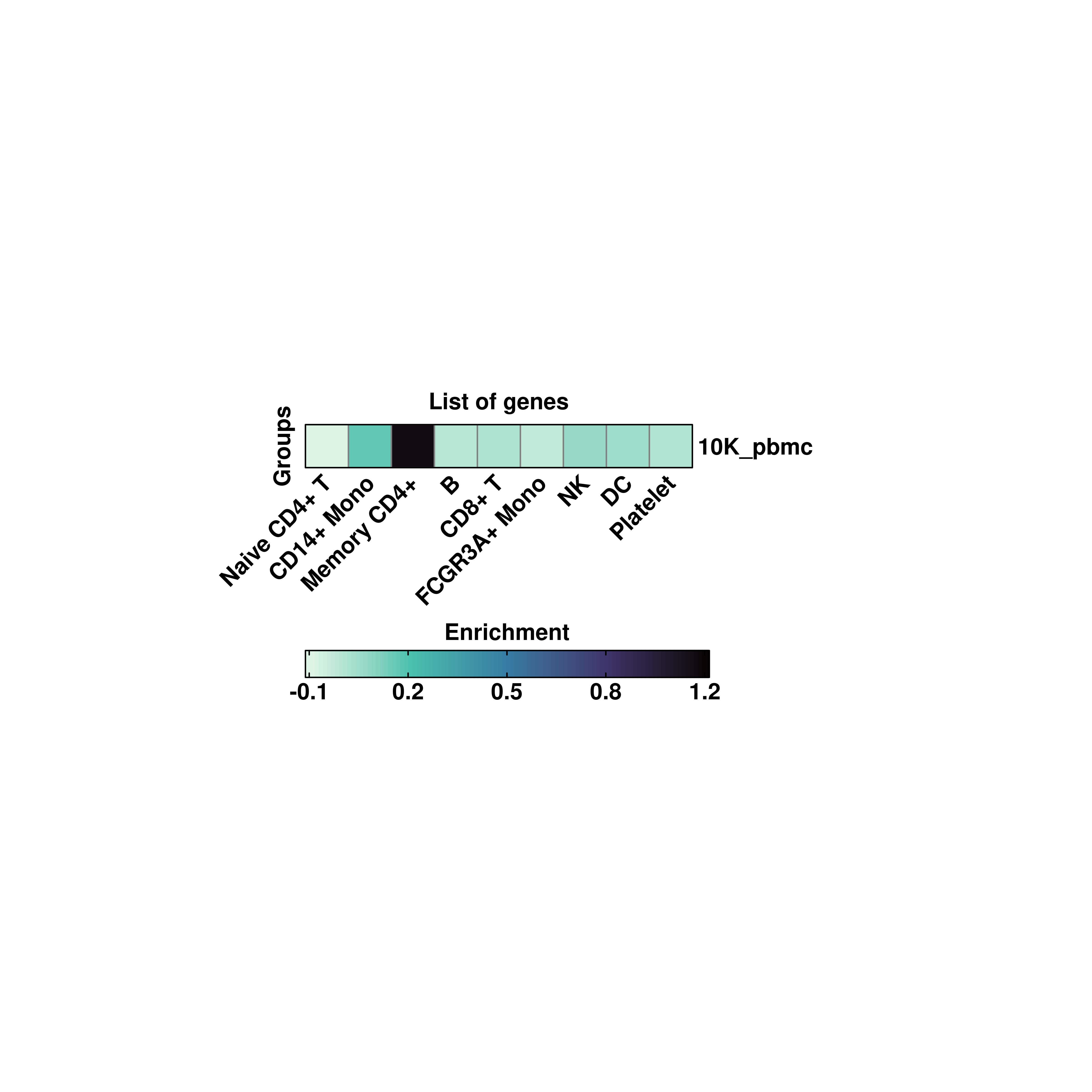
20.2 Several groupoing variables
However, more than one variable can be passsed at the same time to group.by:
# Group by several variables.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
group.by = c("seurat_clusters", "orig.ident", "annotation"),
viridis_direction = -1)
p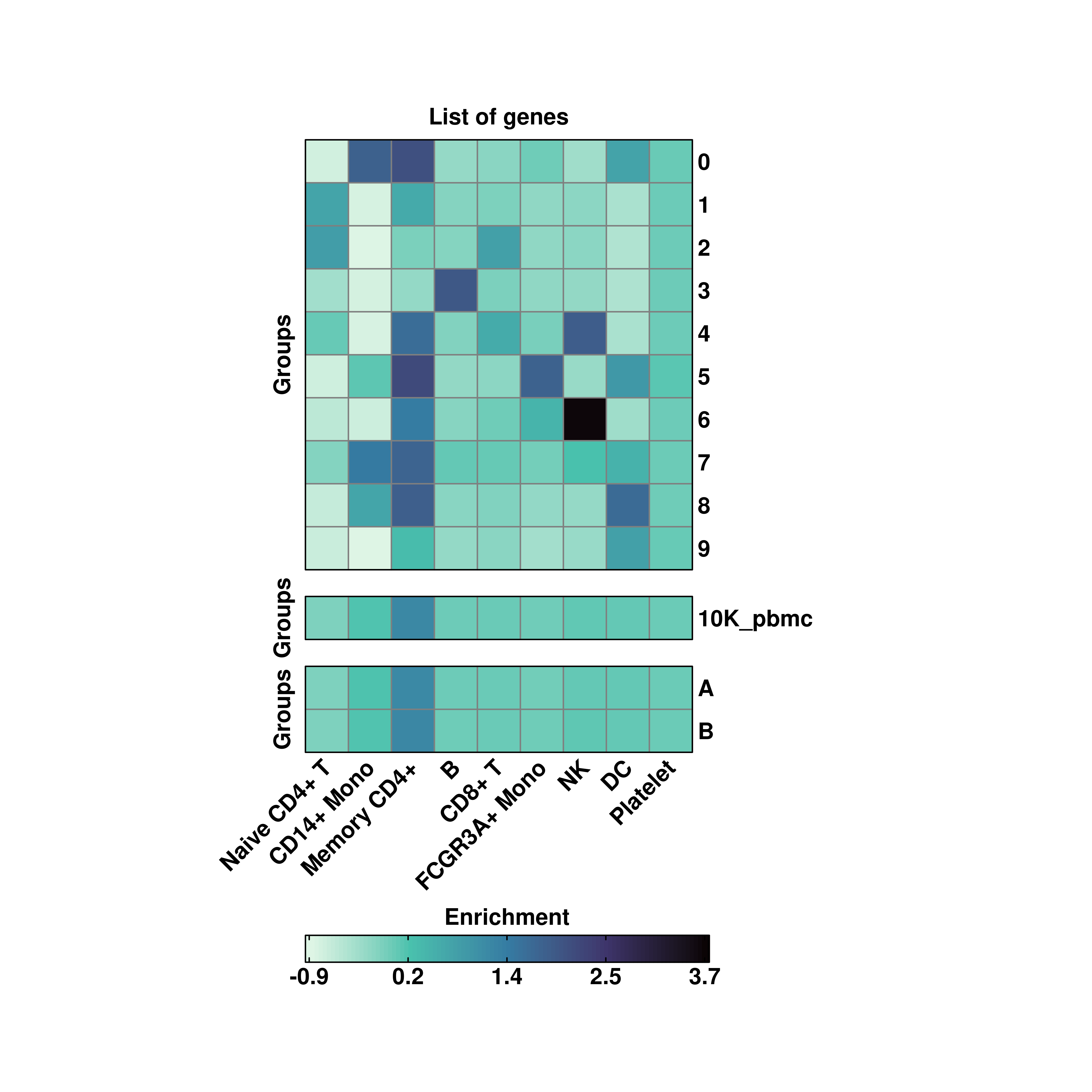
One can also customize the group titles by providing as many characters as variables in group.by to row_title:
# Custom aggregated values.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
group.by = c("seurat_clusters", "orig.ident", "annotation"),
row_title = c("A", "B", "C"),
viridis_direction = -1)
p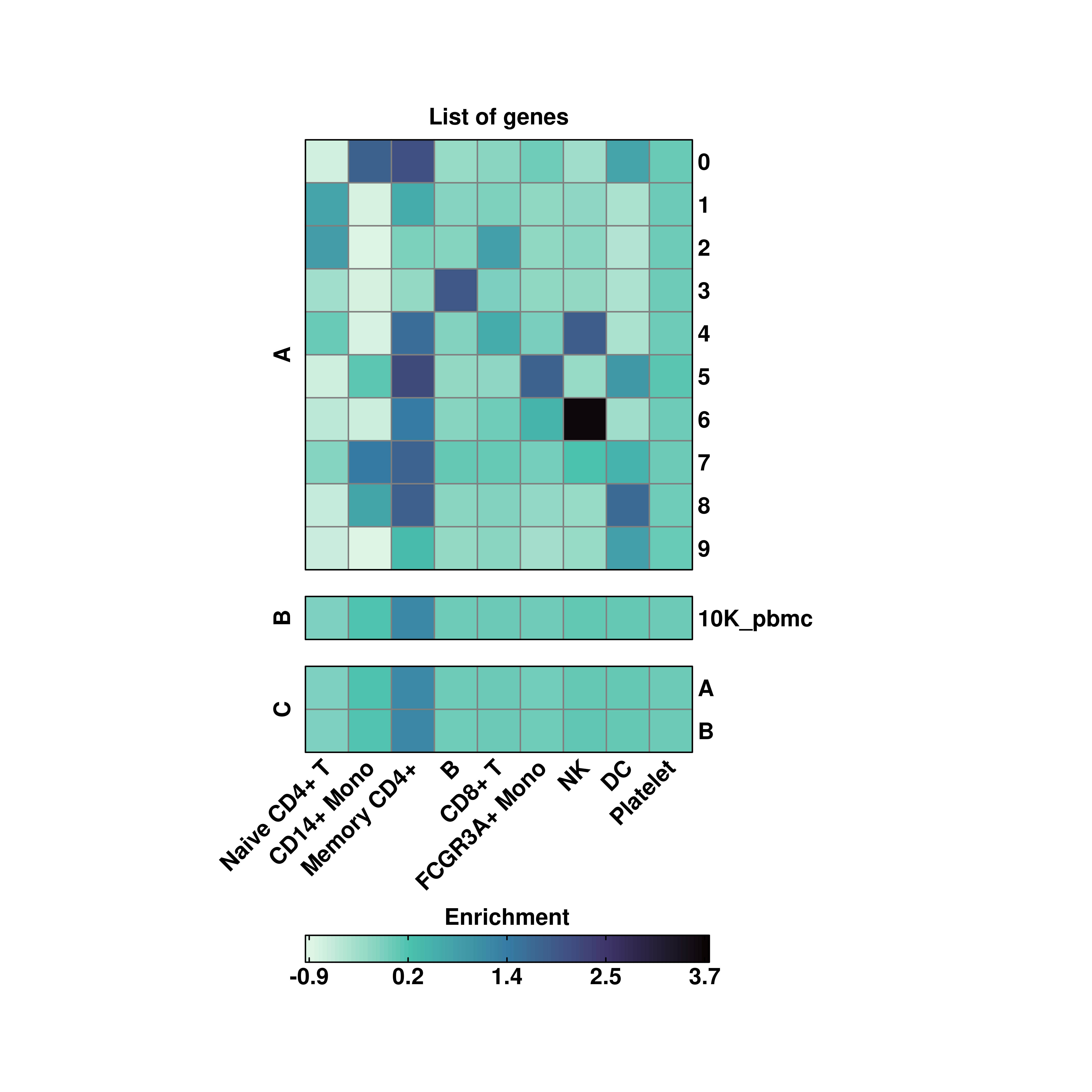
20.3 Transpose the heatmaps
The heatmaps can be transposed using flip = TRUE.
# Transposing the matrix.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
flip = TRUE,
viridis_direction = -1)
p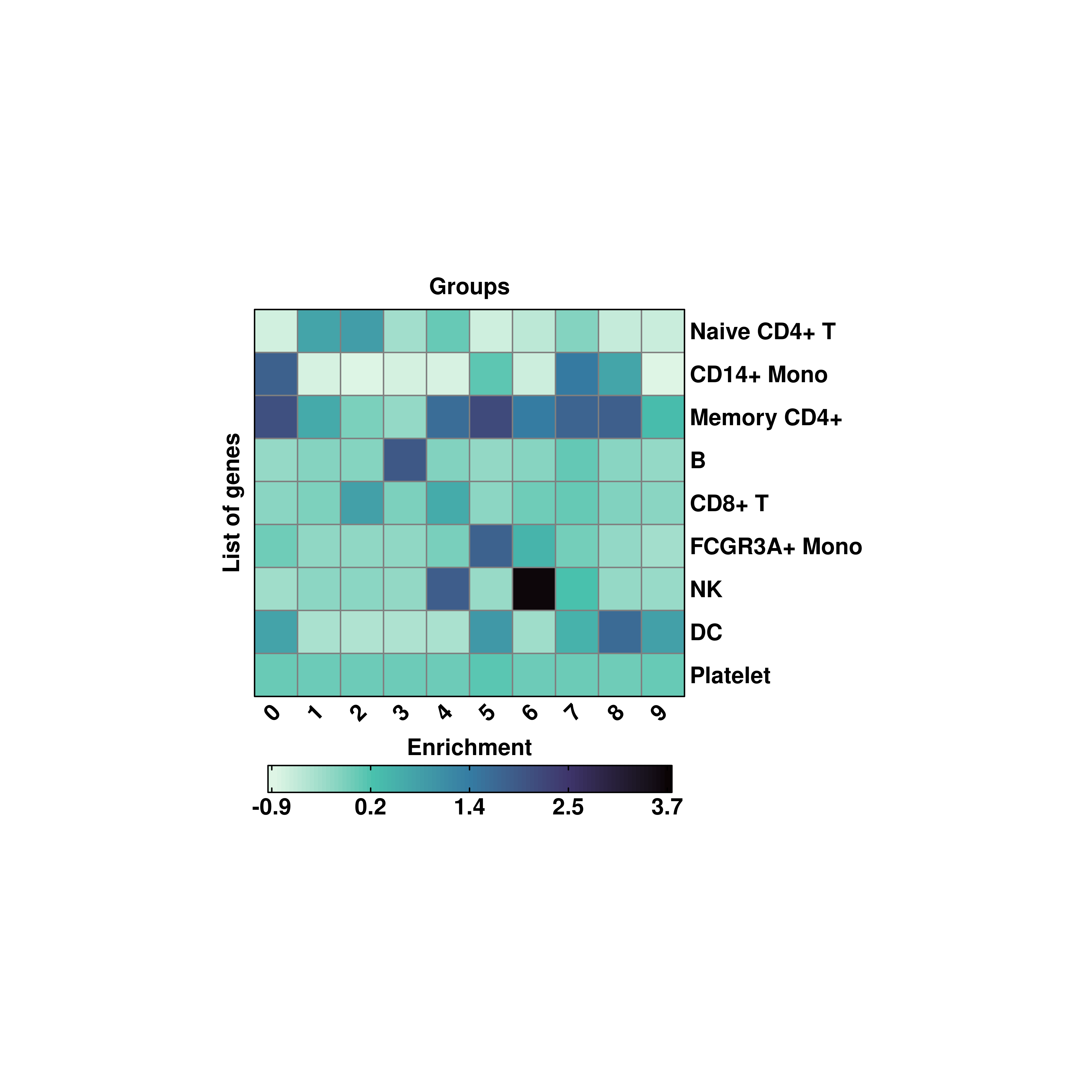
20.4 Modify the rotation of row and column titles
Both rows and column names can be rotated using column_names_rot and row_names_rot parameters, providing the desired angle.
# Rotating the labels.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
flip = TRUE,
column_names_rot = 0,
viridis_direction = -1)
p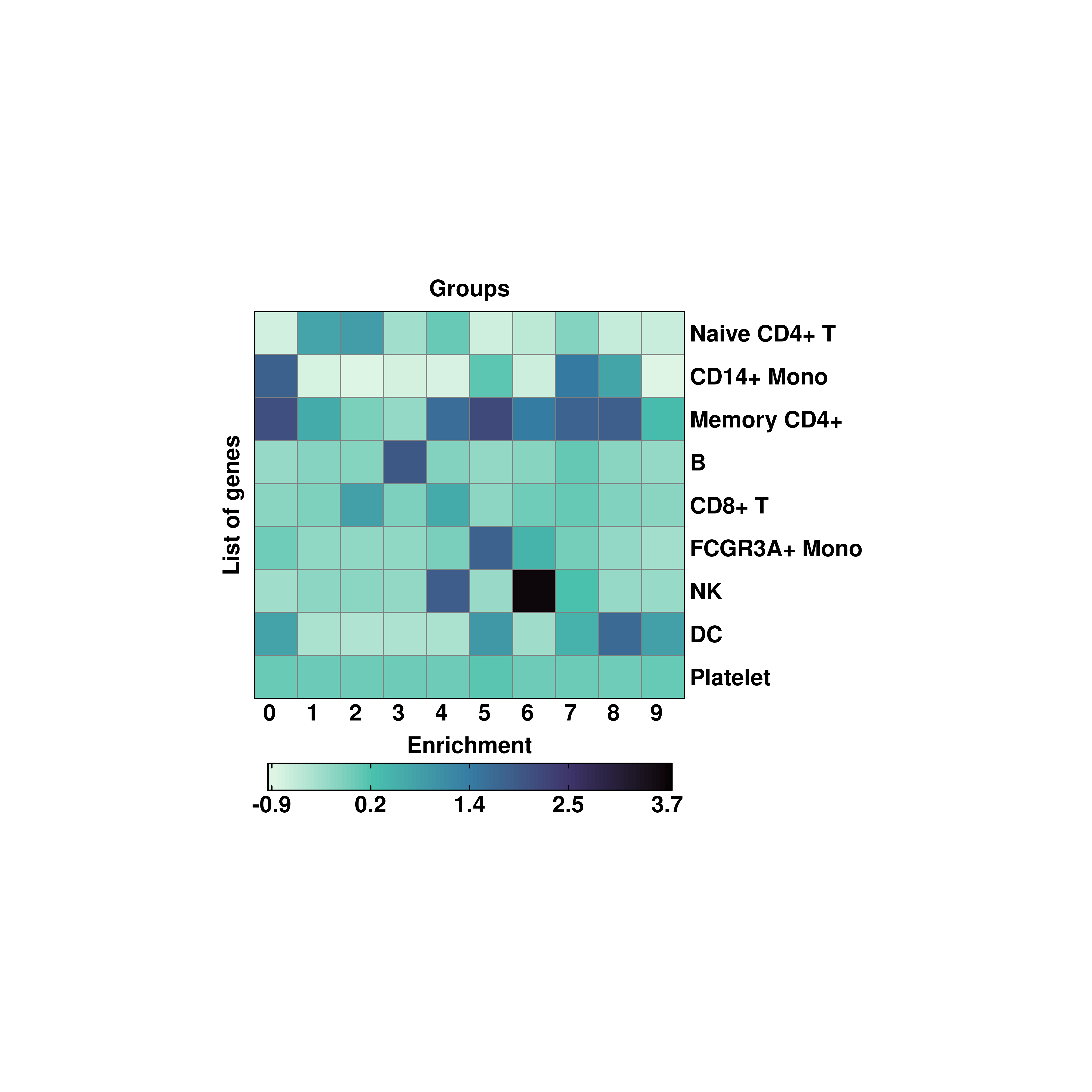
20.5 Changing the cell size in the heatmap.
By design, the aspect ratio of the tiles in the heatmap is fixed so that cells are squares, and not rectangles. However, the user has the possibility to increase/decrease the cell size of each tile by modifying cell_size parameter. This is set to 5 by default.
# Modifying the tile size.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
flip = TRUE,
cluster_cols = FALSE,
cluster_rows = TRUE,
cell_size = 7,
viridis_direction = -1)
p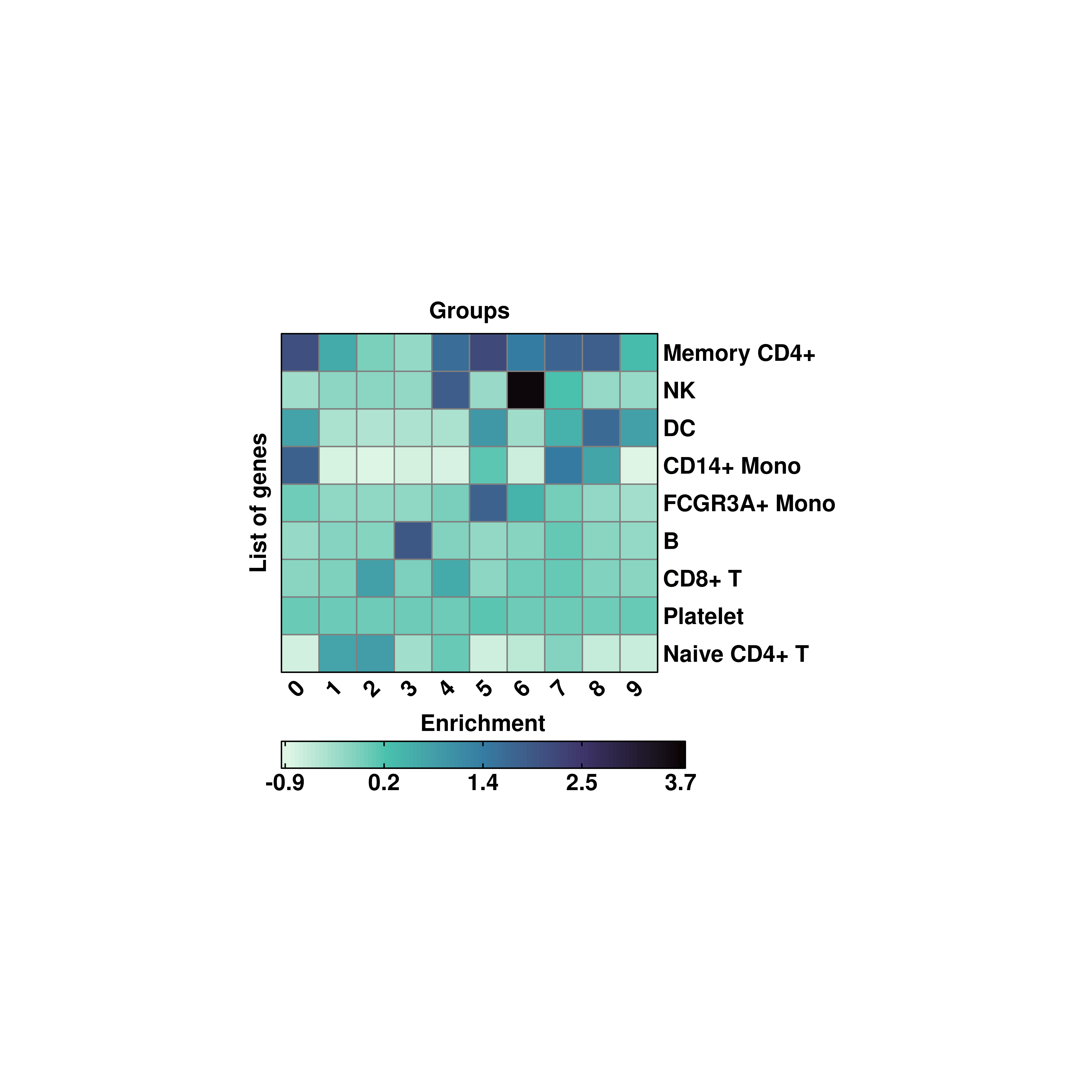
20.6 Symmetrical scales
If one wants a symmetrical scale,
# Symmetrical scale viriis.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
flip = TRUE,
cluster_cols = FALSE,
cluster_rows = TRUE,
enforce_symmetry = TRUE)
p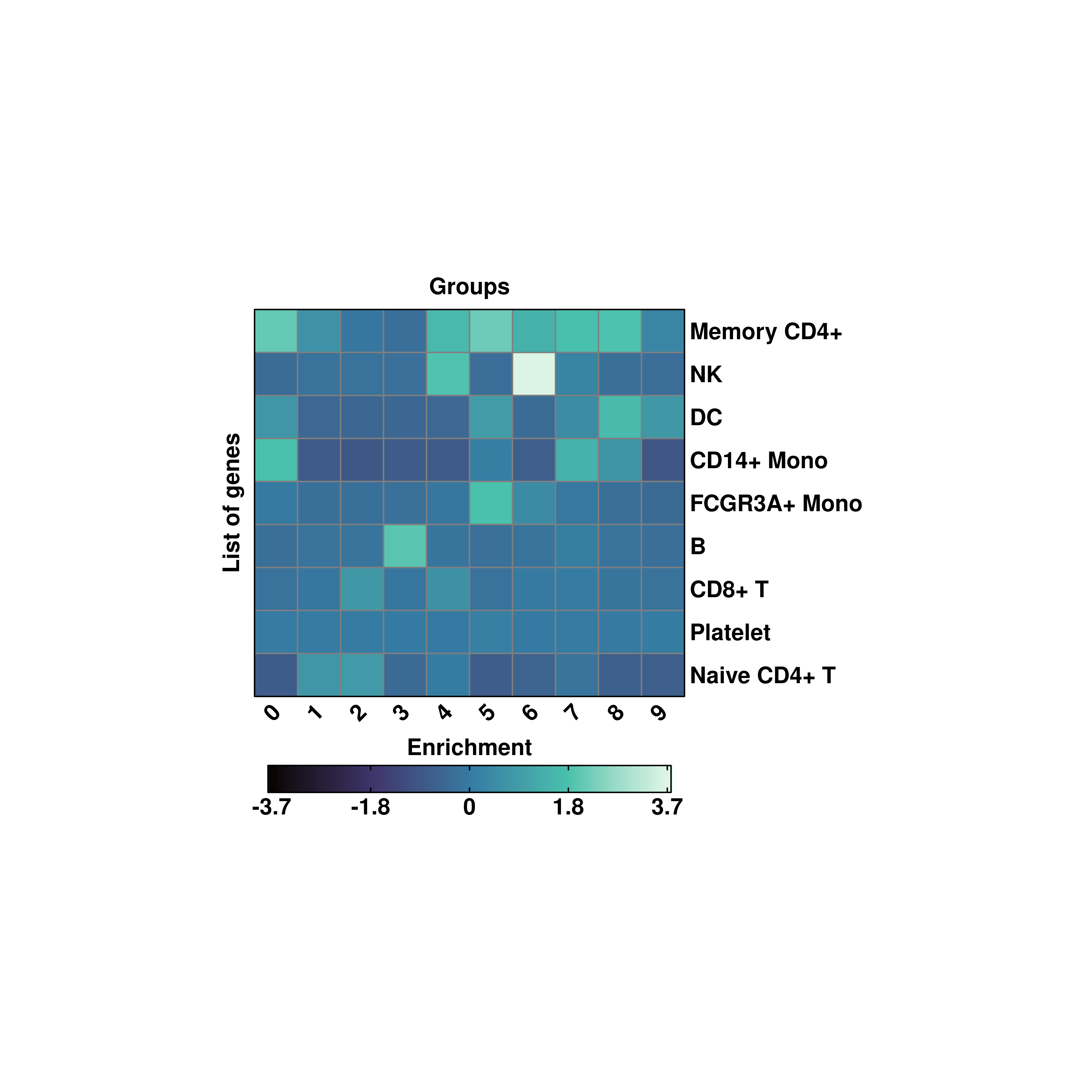
For such cases, it is best to set use_viridis = FALSE.
# Modifying the symmetrical scale non viridis.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
flip = TRUE,
cluster_cols = FALSE,
cluster_rows = TRUE,
enforce_symmetry = TRUE,
use_viridis = FALSE)
p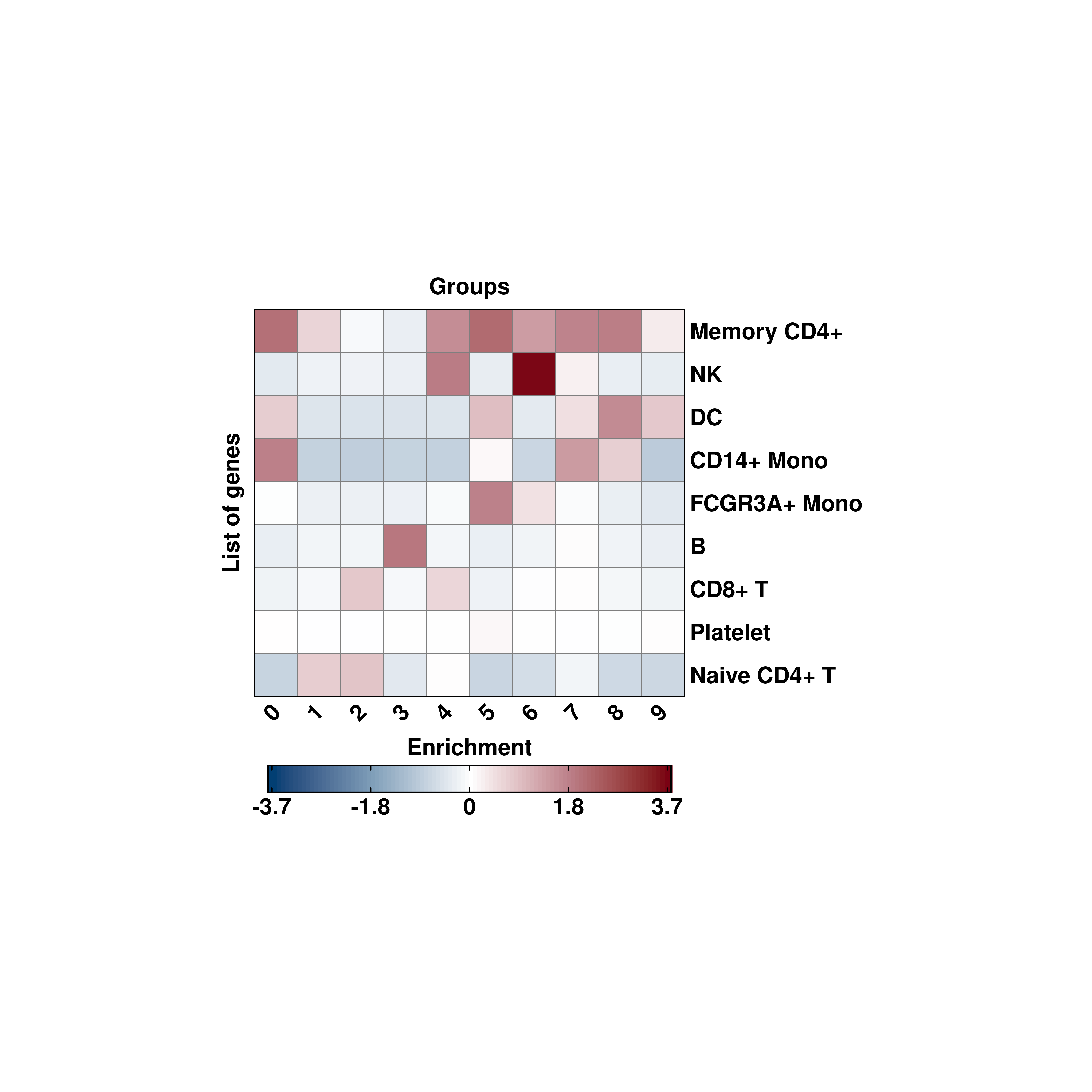
20.7 Compute other type of scorings
Similar to Seurat::AddModuleScore(), other enrichment scoring methods have been developed. One of such is UCell. To use it as scoring method, simply pass flavor = "UCell":
# Use UCell scoring.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
flip = TRUE,
cluster_cols = FALSE,
cluster_rows = TRUE,
flavor = "UCell",
viridis_direction = -1)
p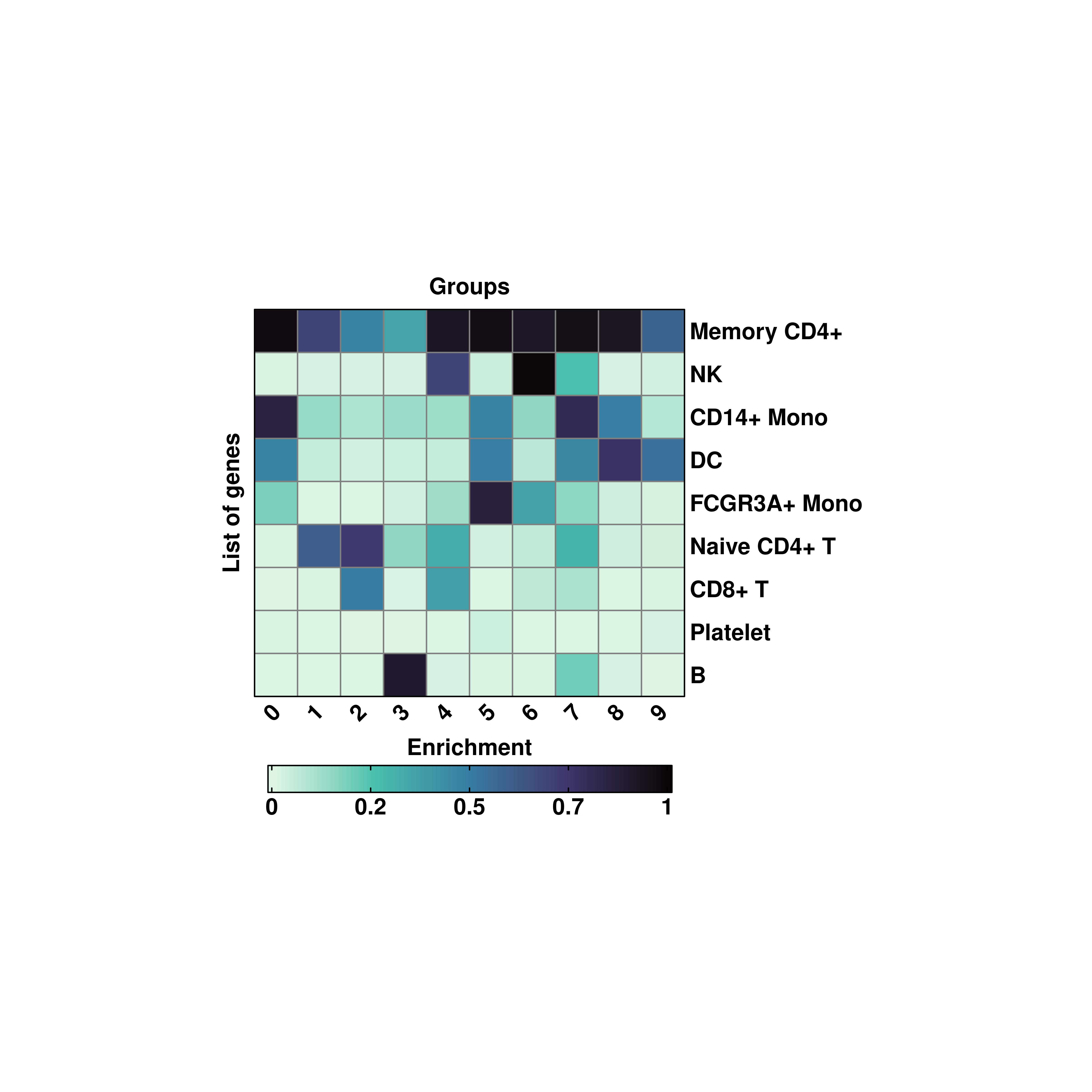
Alternatively, AUCell scoring is also available using flavor = "AUCell".
# Use AUCell scoring.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
flip = TRUE,
cluster_cols = FALSE,
cluster_rows = TRUE,
flavor = "AUCell",
viridis_direction = -1)
p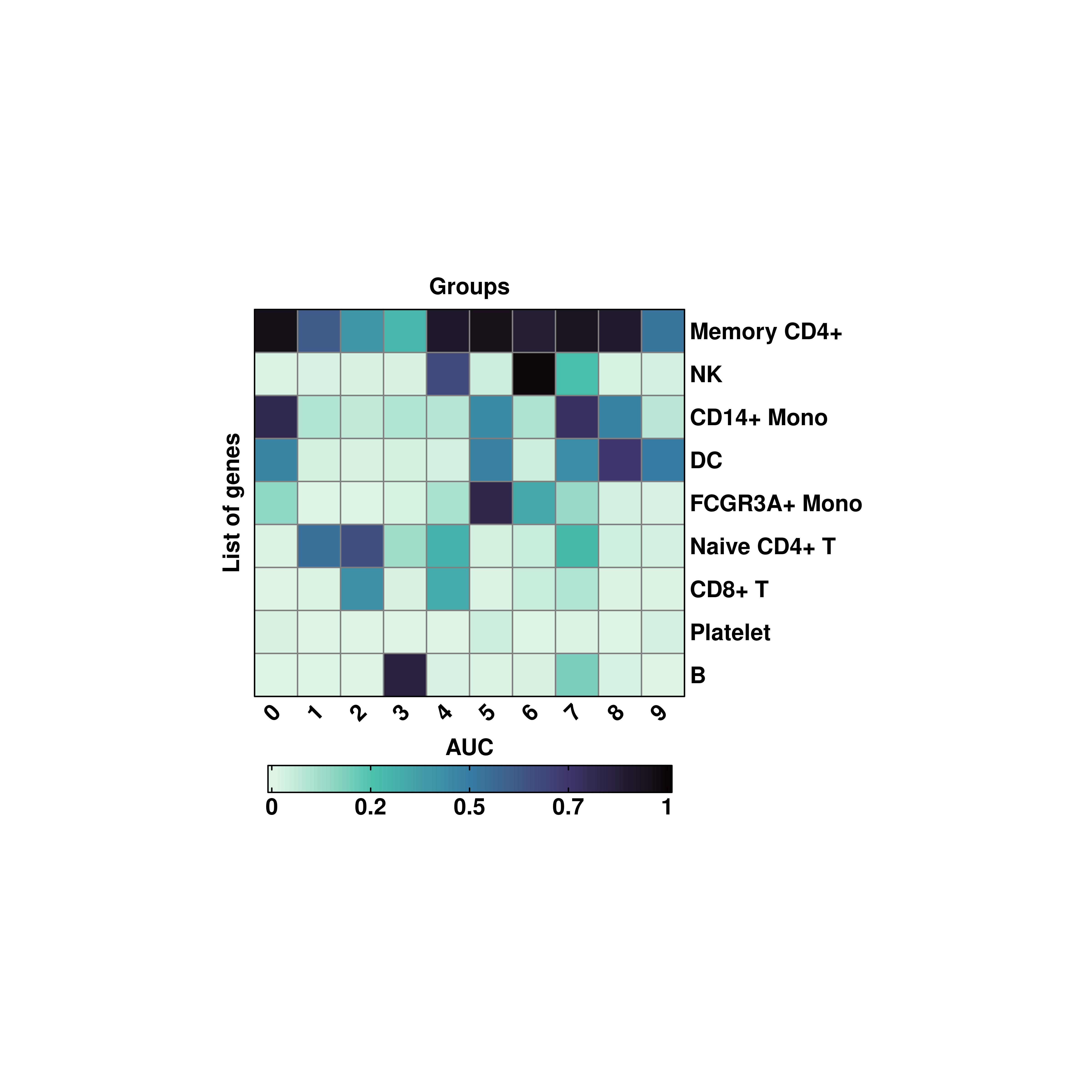
20.8 Subset the color scale.
It might be the case that a single gene set, for a single cluster, drives the color scale entirely. We can treat this as an outlier, so that we can subset the color scale to better represent the values in between. We can achieve that by using min.cutoff and/or max.cutoff.
# Subset the color scale.
p <- SCpubr::do_EnrichmentHeatmap(sample = sample,
input_gene_list = genes,
flip = TRUE,
cluster_cols = FALSE,
cluster_rows = TRUE,
flavor = "UCell",
min.cutoff = 0.2,
max.cutoff = 0.7,
viridis_direction = -1)
p